I’m just getting to grips with distributed database terminology pp130 in “MongoDB The Definitive Guide”
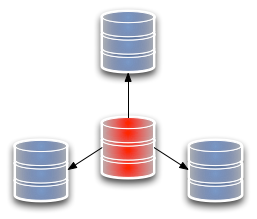
Master-Slave Replication

Master-slave replication can be used for
- Backup
- Failover
- Read scaling, and more
Read scaling could be really interesting from a BI consumption point-of-view eg a peak of user traffic to the DW portal at the beginning of the day.
In MongoDB the most basic setup is to start a master node (in my case the Dell 5100) and add one or more slave nodes (in my case, the Raspberry Pis) Each of the slaves must know the address of the master.
To start the master run: mongod –master

To start a slave run: mongod –slave –source master_address
– where master_address is the address of the master node just started. This is where my previous post on fixing a static IP comes in handy.

First, create a directory for the master to store data in and choose a port (10000)
$ mkdir -p ~/dbs/master
$ ./mongod --dbpath ~/dbs/master --port 10000 --master
Now, set up the slave(s) choosing a different data directory (if on same/virtual machine) and port. For any slave, you also need to specify who the master is
$ mkdir -p ~/dbs/slave
$ ./mongod --dbpath ~/dbs/slave --port 10001 --slave --source localhost:10000
All slaves must be replicated from a master node. It is not possible to replicate from slave to slave.
…As soon as my 32MB SD cards arrive in the post and I install MongoDB on the remaining 4 R PIs I will give this a go!
Replica Sets
 A replica set is the same as the above but with automatic failover. The biggest difference between a M-S cluster and a replica set is that a replica set does not have a single master.
A replica set is the same as the above but with automatic failover. The biggest difference between a M-S cluster and a replica set is that a replica set does not have a single master.
One is ‘elected’ by the cluster and may change to another node if the then current master becomes uncontactable.
There are 3 different types of nodes which can co-exist in a MongoDB cluster
- Standard – Stores a complete, full copy of the data being replicated, takes part in the voting when the primary node is being elected and is capable of being the primary node in the cluster
- Passive – As above, but will never become the primary node for the set
- Arbiter – Participates only in voting. Does not receive any of the data being replicated and cannot become the primary node
Standard and passive nodes are configured using the priority key. A node with priority 0 is passive and will never be selected as primary.
I suppose in my case if I had decreasing SD cards, or a mix of model A (256 MB) and model B (512 MB) Pis, then I could set priorities in decreasing order so the weakest node was never the master and always selected last/lowest priority.
Initializing a set (pp132)